Specifications
Natural language specifications and requirements often precede writing software. They are a version of the information that's written in a language everyone can understand. However, for complex domains natural language specifications often seem to be inadequate or insufficient.
It’s not that natural language is inherently bad. After all, it’s how humans have communicated for millennia. But here’s the problem: natural language is infuriatingly, and catastrophically imprecise. Consider the word "break." Depending on the context, it could mean "to smash something to pieces," "to make a sudden dash," or even "to crush the spirit of". Now, imagine trying to pin down a complex software specification with such slippery words. This is a result of human language often being vague, polysemic and contextual. Look at how many meanings "break" has.
Human language specs often go beyond the limits of the language. It's a problem for complex projects such as, for example, web browsers, which need to have a standard specification for interoperability. Browsers based on a human language spec instead of a reference open source implementation serving as the spec, are slowly going away. And it's not because there weren't huge efforts to get the human language spec into shape by using english crafted to be as precise as possible, often quasi pseudocode. See this excerpt from the html5 spec:
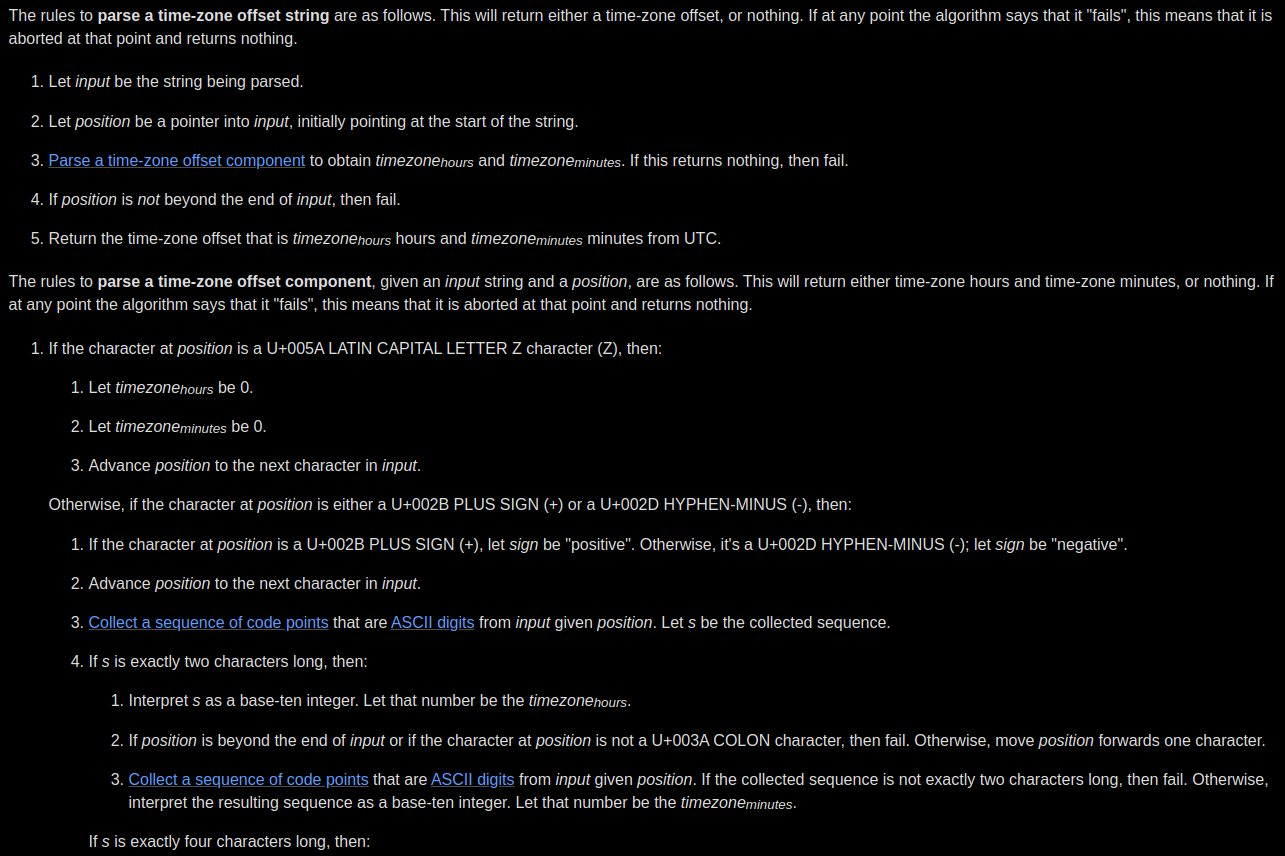
But in the end, if you've used Firefox in the past few years, you've likely regularly hit broken pages or components on websites. It's just too difficult to specify everything in imprecise English. Trying to engineer through a non-code specification is one of the main reasons Firefox might be falling behind and that only chromium/webkit based Browsers seem viable.
Code doesn’t suffer from the same polysemy as natural language. It’s exacting, and unambiguous. Code being the ultimate specification language is supported by the theories of Kolmogorov that suggests that fully specified information distills down to computer programs.
There is also a history of trying to improve things by mixing both natural language and code, for example with Donald Knuth's Literate Programming a brilliant attempt to marry the two which might have led to the concept of having "doc comments", code with extractible inline comments. Modern platforms with pull request based workflows that tie discussions to version controlled code also follow these principles.
Complex specs are also best written iteratively, using a kind of scientific process where real world knowledge is used to refine and reduce uncertainty in requirements over time. Version control and modern software dev tooling are great at supporting this kind of evolution.
There are of course, some valid concerns with code based specs. Not everyone can read them. And while natural languages tend to under-specify, reference implementations tend to over-specify. Reference implementations can also unduly tie specs to specific hardware, OSs and platforms.
But there's the thing, over-specification is less of a problem than under-specification and it can be mitigated by splitting off or hiding particular blocks of code as implementation details, labelling them as not part of the spec. Test suites can alse be designed to avoid over-specifying by asserting on higher level requirements instead of details of specific implementations.
Now the fact that specs can be better written in code highlights the importance of engineers knowing the domain well. It's very difficult to split the task of good spec writing from good software engineering.
Great engineers are those who have absorbed the nuances of their field, who can translate complex knowledge into precise, executable code.
This concept of translation of expertise into specialized languages applies outside software development. It's the reason, for example, why legal translators require both a degree in translation and a degree in law. They’re not just swapping words between languages; they’re navigating a labyrinth of meaning, intent, and legalese.
The ideal codebase for a complex domain is a living encyclopedic document that maps out the problems and solutions in the domain with the precision of a cartographer, and evolves into the ultimate repository of knowledge about this domain.