Leaning into complexity by reducing code entropy
This is an attempt at unearthing from first principles, timeless patterns we can rely on to build complex software. It's often said by engineers, that you should keep software as simple as possible. But simple is difficult to define. The only technical way I was able to make sense of it was in terms of minimizing Kolmogorov/Solomonoff entropy, the same measure language models target to achieve intelligence. It's about managing code entropy to maximize the chances software working beyond known requirements while minimizing the surface for breakage.
I previously mentioned Minimum Description Length (MDL). The concept can be used to decide on abstractions that best deal with complexity and uncertainty. This post will build on that and also touch upon the related concept of Dependency Length Minimization.
MDL is the removal of extraneous bits from programs, the same way scientific notation removes extraneous digits from numbers.
The central idea is that computer programs are equivalent to mathematical models and vice versa such that you can reason about computer programs as models.
This is the main insight behind MDL, Kolmogorov complexity and Solomonoff induction. These statisticians figured out at some point that math equations, as a language for statistical models, were too limited. Things like linear regressions or simple ML models were not enough. Models needed to be augmented by if statements, loops and other constructs, they needed to be Turing complete.
That is, models were not to be just inputs and outputs and math equations with parameters but they were to have inputs and outputs, plus a language, a grammar that defines a mechanism of computation. Even though this grammar, as a special case, can just be math equations, it can also be something more, like a full programming language.
This means that on the flip side, you can think about programs like models to understand their information theoretic properties. You can count the bits that are needed to describe the logic and this tells you things about how well the model is tuned. You can calculate similar measures you might calculate on statistical distributions of math based models. You can try to find MDL, the smallest program that can describe the solution which is a form of entropy, like entropy of statistical distributions, measured in bits.
The number of essential bits of logic in a program tells us something about information content and uncertainty of the program, about its state of knowledge and how well the program fits knowledge and data about the domain.
MDL takes into account entropy of different aspects of programs. The shape and structure of the program, the dependencies between different parts of the program, the data about the domain that's embedded in the program, how it encodes problems and solutions.
This applies to the very basic constructs of programs. The bit width of an integer can tell you about the precision or uncertainty of that value. If you use an 8 bit integer to represent a range of values, you have less resolution and more uncertainty than using a 32 bit number to represent the same range.
It is not automatically better to use a higher resolution. Extra bits that go beyond available knowledge add noise and can lead to overfitting and poor generalization. That's why, using a precise minutes-hours-seconds timestamp when you want to represent just a date can cause edge case bugs when doing operations over those timestamps. Using more bits than is warranted by the knowledge being represented generally leads to overfitting and overfitting leads to extraneous incorrect details (sometimes called hallucinations in the context of LLMs). [1]
Most ML algorithms attempt to achieve generalization to various degrees and "smooth out" the probabilities when data is limited. What some mathematicians figured out was that the optimal Bayesian inductive bias to reduce overfitting is equivalent to minimizing the program size that generates the data, a mindblowing result that makes these principles apply to programming.
This works with strings and other data structures, not just numbers. Though you have to think in terms of grammars and randomness or uncertainty that might look like the output of fuzzing.
Description length minimized programs abstract and interpolate to unknown cases better. But why is it important for programs to generalize and interpolate well? Can't we just spec out all the requirements thoroughly and build the exact program that we need? Why do we need things to work for unknown use cases?
You sometimes can spec out everything, if your domain is simple enough. But for some domains, as you zoom in on the details, you uncover vast amounts of edge cases, very large amounts of bits of logic to resolve. Often too much to spec out comprehensively in a reasonable amount of time. On top of this, the details are often too intricate to describe in natural language. You need code. And it helps for this code to have good information theoretic properties.
I want to mention in passing that this challenge is also a business opportunity. I would go as far as saying that the problems where you can specify the full requirements are the already picked low hanging fruit of the software eating-the-world revolution. For new generation software, it might be necessary to push into complexity and uncertainty to get ahead of the pack. This ties into fundamental Schumpeterian efficient market dynamics.
I work in software automation of finance and accounting and this is a field where complexity is very high. Lawyers are always thinking up new equity contracts and clauses that interact with complex accounting rules or bureaucratic tax requirements. The problem space is very high dimensional.
Software products have many features. The potential for cross feature interactions is at least N squared the number of features as each feature can interact with each other. It often does not take less time to solve a complex interaction between features than to build the initial version of a feature. So if, for example, a team builds 20 features in a couple years, it might take 400 projects to solve all the potential interactions and 40 years. And then you can also have interactions between interactions, sub features interactions, and in a changing world, the work doesn't stop here since there is a need to keep up with evolving domains. It can be a huge amount of product engineering to be comprehensive, and have full edge case coverage of a complex domain. For example, Stripe which solves sending money from point A to point B, claims they merge over a thousand improvement PRs to their software per day. That's the pace sometimes needed to progress on complex high dimentional domains.
Unsolved edge cases look like bugs to users. On the engineering side, I find it's useful to distinguish between actual bugs, something that was not built to spec, and incompleteness "bugs", when everything was built correctly to spec but the spec had been scoped down, it didn't sufficiently zoom in on all the relevant details that users tend to encounter. If you think about requirements as a map of the problems and solutions of a domain, that map had too low of a resolution.
The reason it's useful to make that distinction is that the solution for each type of "bug" is almost opposite. If your codebase has many actual bugs, the solution might be to increase testing and QA. If, on the other hand, your problems are caused by not having covered the details and edge cases at a high enough resolution, development velocity is key and more testing and QA might actually slow down implementing the missing details and leave your code with more problems. Different areas of a code base might suffer from either of these issues to various degrees.
MDL, reducing entorpy, is one strategy that actually helps for both types of issues. It can maximize coverage of the problem-solution space by raising the chance that the solutions work beyond the known and tested cases while at the same time reducing the surface for bugs.
This means following MDL principles allows you to to write software in a way that generalizes as much as possible to more use cases without having to test or even know about all these cases. The code will naturally exhibit more intelligence.
One thing to note here is that it's not just minimizing the program that can generate the data. It's the program that does generate the data. In the context of building software, this means not just the software itself but the suite of tests that represent the knowledge about the problems the software is trying to solve.
With streamlined, well abstracted, minimized and tested code, if you can implement a certain amount of sufficiently representative use cases, the system will more likely work for other untested cases.
One reason MDL works is that if you have found the minimum program that works for N known cases, instead of implementing the N cases separately in a longer program, it's more likely it will work for N+1 cases. You have found a common pattern that works for many cases. Finding the smallest possible pattern, also means there are fewer ways it can be wrong, the space of alternative similar hypotheses is smaller, their Bayesian prior is higher.
The gold standard for good abstractions to me has always been something like Unix and Linux. Linux's abstractions have been so good that Linux is a core part of some of the most complex systems in the world and reached popularity with zero kernel unit tests (until they integrated KUnit only in 2019)! This is the power of good domain abstractions based on solid domain expertise ( the counterexamples are Multics and Hurd with their componentized architectures and microkernels that caused progress in both projects to grind to a halt ).
What does overfitting, or non description minimized code look like?
Well there's just the plain known things to avoid, the overly duplicated logic, the completely unabstracted script like code, code that completely fails to follow DRY principles. Then there's things like lack of encapsulation and global state (This falls under stretched dependencies which I'll talk about more later).
Starting from an unbiased representative test suite
One of the most difficult things when dealing with data and knowledge, when building models, is that you usually start from a training data set, requirements or tests, and this data can be biased in subtle ways that results in bad fit to the real world.

Your suite of tests should represent users' concerns in the least biased way possible. It's easy to end up with features that go into too much details for areas that maybe specific users want but that is noise to the rest of the market. A more common flaw is code and tests that overweight coverage of things that engineers care about and underweight things that users care about. You'll have structures and abstractions that describe things in a way that engineers think about but is difficult to relate to for users. Bias is a very difficult problem, it plagues scientific research, contributes to the replication crisis etc.
With a test that asserts on something that users don't care about, if that test fails later it will be a false failure. When there are multiple ways of implementing something and it doesn't matter to the user which one you pick, it's a good idea to avoid tests that assert on a specific way. Otherwise it leads to a noisy test suite, difficult future refactoring and poor abstraction and generalization. It is sometimes said that lack of flexibility to refactor and improve the code base can lead to "big ball of mud" architecture. Tests should reflect users desires, not a specific implementation of them.
An overfitted test suite also means that it's simply a poor description of the requirements, a poor embodiment of the state of knowledge about the domain (in the Bayesian sense).
Dependency Length Minimization
Now I also mentioned Dependency Length Minimization. How does it tie to Minimum Description Length? This is an interesting aspect, it's fundamental to languages including programming languages.
I'll give a few examples going into psycholinguistics and information theoretic roots.
Here's a basic example of Dependency Length Minimization for natural language.
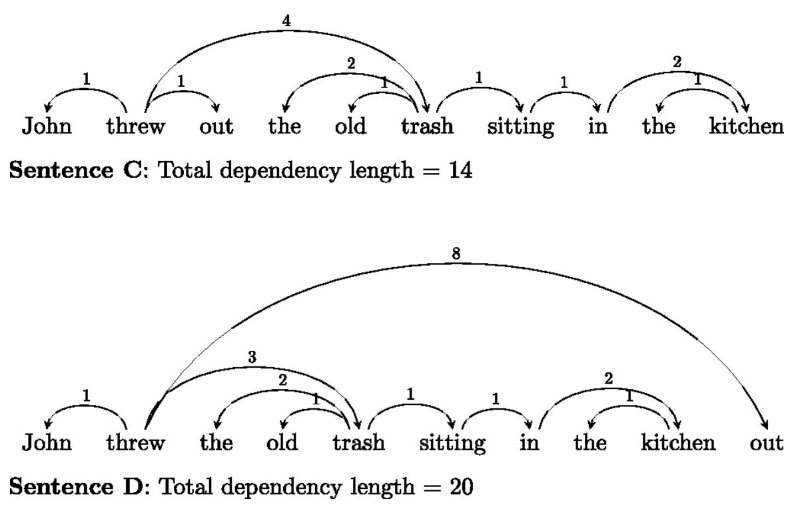
Even though the two sentences have the same meaning and same words, the top sentence's dependency length is better minimized than the bottom sentence's making it easier to parse and read. If you have Sentence D, it might be a good idea to rebalance the parse tree by moving the words around to Sentence C (dependency graphs have equivalent parse trees). Note the similarity between dependency grammars and attention mechanisms.
Why is dependency length minimization important for minimum description length? It's because long referencial distances add a significant amount of entropy.
The thing about MDL is that it really applies to the smallest form of a program. A program that is potentially minified or even compiled and compressed. Basically a program once you've removed everything unnecessary for interpretation. We're talking a form approaching pure irreducible logic, a program approaching its Shannon limit.
I wish it would be as simple as reducing lines or characters of code but to be accurate, you have to think about the amount of logic in units of bits that code represents. However they are correlated so thinking about high level code length is a good starting point.
(Thinking about compressed logic is also interesting because of the well known relationship between AI and compression)
One clue that dependency lengths are important is their effect on potential for compression.
Compression algorithms usually depend on related things being together. People have noticed that, for example, the way an OS or library orders files could have a huge impacts on the final size of the compressed version of those files.
Compression algorithms often have two main components. They use entropy coding such as Huffman Coding to write more frequently occuring patterns using smaller symbols. This often gives you a good amount of compression by itself, depending on the distribution of data. On top of this, there's usually a mechanism to avoid compressing repeated blocks of data by referencing previous blocks instead of encoding duplicates (note the similar shape to "attention" mechanisms). For performance reasons, usually the algorithm only looks back so far for duplicate patterns which is one reason keeping similar things together helps. But there are also limits from the fact that longer back references take more space to store. If you are looking only within a 256 offset window, you can store the back references in, at most, a byte. Larger windows require on average, larger size of pointers for back references, negating some of the benefits of the compression.
If you were trying to compress a theoretically incompressible very large block of fully random bytes, even though you could probably find duplicate patterns in random bytes, trying to compress by creating references between them would not work because the average size of the references themselves would offset the compression gains from the deduplication.
Similar principles apply to compiled programs. Compiled programs replace named variables by memory addresses and the more variables are near, the more references can be specified by smaller relative addressing modes. This not only applies to data memory addressing but to code addressing. Near JMP instructions addresses can theoretically be encoded in fewer bits.
What's the use of thinking about all this? I don't care much about the performance gains of generating the smallest possible program. Computers have plenty of memory nowadays. The important thing is that MDL principles say that this minimization also means the models' abstractions are optimized for generalization and intelligence.
Reducing the size of back references, not only reduces the minimal size of programs but does so because it reduces the average area, the scopes that needs to be looked at when trying to parse, understand and interpret a piece of logic having references. This means, it reduces the amount of logic needed to be understood when modifying a piece of code or interpreting and executing the code.
This helps reasoning about the program in fundamental ways.
In the case of natural language, it doesn't just help humans. One place where this helps is when using LLMs. Neural nets only started to get really smart when they adopted the attention mechanism, which I would argue is a mechanism to sort out dependency trees.
When dependencies are stretched out, because information is spread out, LLMs have more difficulty following the references. They even sometimes have to resort to inferior RAG schemes when the length of references overflows context windows.
Stretched dependencies makes it more difficult for information to find parent information in the parse tree. The problem might even be worse when working in the other direction. When the average dependency lengths are long, there's much more area to cover to find and understand all dependent pieces.
As for code, when you are modifying a function that has multiple faraway dependants, when your function is called by many faraway pieces of code, it takes much more time to survey and understand what the impact will be on the dependents when they are spread out in a vast area than if your function was called, say, just once in a block of code just below.
This problem is better known for run time dependencies. Modifying a global variable that is broadly referenced makes it difficult to track logic, one reason why functional programming styles try to minimize the scope affected by state changes.
It's probably worse for run-time state, maybe because state changes more often than code. So it's generally well established that using a lot of global variables is bad practice. However, having a lot of complex functions accessed by a wide scope when they are still evolving and being iterated on, is not unlike using a lot of global variables. Tight scopes are important to maintain the ability to innovate and change code in an orderly way. Short dependencies are equivalent to tighter scopes.
So how do you minimize the length of dependencies in your code?
I'm going to write some examples in Golang. Go is a great language to do this because it seems to have been designed with dependency length minimization and minimum description in mind. I would be curious to know whether the authors of Go explicitly had something like this in mind. It might not be a coincidence that some of them came from Bell Labs where Information Theory was devised and they worked on Unix which was an effort to make Multics into a more unified and tightly integrated whole versus the previously too modular Multics.
Golang, by eliminating exceptions, eliminated huge jumps to catch blocks in faraway callers. Keywords like defer helped bring logic that was going to be pushed down by the body of the function back to the location of the code it's related to. The := vs = distinction makes it harder to accidentally modify state that was meant for a broader code area and keeps new state to a more local part of the function. Authors of Go made scoping down a global variable to be private, thus reducing the potential for lengthy external dependencies, as simple as using a lowercase character instead of uppercase. This operation was so important it was blessed with, information theoretically speaking, the smallest possible discrete 1 bit change (sixth bit in ascii/utf-8).
Reducing dependency lengths is often about inlining code. John Carmack calls inlining, engineers "made constantly aware of the full horror of what you are doing". I think that's one benefit. But it's even more beneficial from the other direction. As I mentioned, when modifying broken out code, you might have to check all the places that are potentially calling it to understand what the effect will be on your program. It's easy to forget to survey dependent code, especially when it's far away even with the help of modern editor tooling.
The benefits of inlining go beyond being aware of the "full horror" that is being executed but also reduces the average scope of logic, it reduces the search space for interdependencies.
There are different patterns that can be used for different levels of inlining.
The plain inline logic.
func main() {
lang := "ENG"
if lang == "ENG" {
fmt.Println("Hello, World")
}
if lang == "CHI" {
fmt.Println("Hello, 世界")
}
}
Anonymous inline functions are a way to break logic into its own block but keep the dependency short
func main() {
lang := "ENG"
fmt.Print("Hello, ",
func() string {
if lang == "ENG" {
return "World"
} else {
return "世界"
}
}())
}
The above might be a ternary operator (?:) in other languages. You can assign an anonymous function to a variable to get a named inline function which puts the dependency slightly further above where it's called but you get the benefit of potential reuse multiple times within the body of the function.
func main() {
greetingFn := func(l string) string {
if l == "ENG" {
return "World"
} else {
return "世界"
}
}
fmt.Print("Hello, ", greetingFn("ENG"))
fmt.Print("Hello, ", greetingFn("CHI"))
}
The reused code is very close to where it is being used. An engineer modifying this, can be very confident they aren't breaking something elsewhere.
Note that inlined functions may or may not reduce overall dependency length. If it's not short and it spreads the body of the function, it may stretch out other dependencies. One way to rebalance might be to put the function at the top of the body where it doesn't split other logic apart, but of course, at that point you only have to go two lines further, not stretching the dependency much more, to make it a file level function that can be reused in other functions which might be worth it in a lot of cases.
func greetingFn(l string) string {
if l == "ENG" {
return "World"
} else {
return "世界"
}
}
func main() {
lang := "ENG"
fmt.Print("Hello, ", greetingFn(lang))
fmt.Print("Hello, ", greetingFn("CHI"))
}
The next positions of dependencies from shortest to longest might be at the top of file, to indicate many functions in the rest of the file use it, in another file in the same directory and package, in a file in another directory or package, in a file in another package separated with an interface, in a separate repo completely.
Monorepos provide a lot of flexibility for doing this kind of rebalancing.
Stretched out dependencies are spaghetti dependencies. The cure for that is a pruned, balanced tree of tightly scoped dependencies.
Breaking out code should also communicate that you have made it solid enough and general enough for reuse in the wider scope you have lifted it to.
The code should be more tested, more simplified, more documented, more stable, more functional, more protected by transactions since it potentially has broader impact on the system.
Even for code you eventually intend to lift out of the current scope, it often makes sense to leave it in a smaller scope while it's incubating, until it's sufficiently refactored and solidified for broader re-use. Otherwise you might end up coupling features together too early with incorect abstractions that will be difficult to change once they're broadly used.
When you're lifting code to be very far, to a very wide context, maybe in separate packages, separate repos, given the significant lengthening of the dependencies and broadening of the context space, it makes sense to have higher requirements at the boundaries to contain that extra entropy. More engineering resources might need to be allocated. With higher entropy comes higher costs to manage that entropy. Oftentimes, it makes sense for the more global state and logic to be protected by a functional, transactional language like SQL.
This is also about diffentiability of code, another concept borrowed from neural nets. Diffentiability is about how easy it is for programs to evolve through small iterative improvements. It is a key aspect of systems that generate language and code. Too many things connected in broad scopes means poor differentiability, small changes having broad unpredictable impact.
These principles explain why prematurely splitting code into microservices can cause so much chaos.
Complex, top level, global logic that is broadly referenced is something to minimize because it means high entropy. When I see microservices like patterns, systems made of a bunch of blocks at the top level, (especially if they are separated by queues, or connected by a multitude of APIs, stretching the dependencies further and preventing transactions and error back propagation), I always want to ask, hey could some of these blocks have been folded in as sublocks of other blocks to narrow their scopes and keep things more hierarchical, keeping communication more local? And also since the upper layer of logic is more risky, could the remaining higher level blocks have interfaced through a safer transactional layer like postgresql, instead of through a mesh of APIs and queues?

Ideally, the code base is constantly being rebalanced like a database building its optimal b-tree index of data. You're building the optimal tree of logic by rebalancing the scope of your dependencies to fit the knowledge and requirements you have about your domain. Even though, when a project becomes large, it'll eventually likely have lengthier code and longer dependencies, there is no rush to get there. Building the final tree without having accumulated the knowledge and data for its layout, can lead to getting the structure wrong. It would be like a database trying to build its final b-tree index before having the data in the table, hoping the index will fit the future data when it arrives. Prematurely breaking out code out also violates Bayesian principles of staying calibrated to the current state of knowledge and updating as you get more data.
There's a few reasons why doing the opposite is so attractive. I used to think that was the way, until some difficult times with microservices made me rethink my assumptions. Many people take as common sense that logic should be split into small components with well defined and stable interfaces.
One reason is that it seems like a self evident good idea to test each sub component in isolation. But even this can have significant downsides.
I think another reason is that as a system matures, it naturally evolves towards the best abstractions which will often have good top level isolated components. Some engineers, having seen a mature, successful codebase will want to mimic that success too early.
Doing so ignores that the successful code base probably evolved from something much more integrated and agile and that the level of knowledge about the domain and users needed to know exactly which components should be lifted out of tighter scopes is often very high and if you lift out the wrong ones too early, you're likely to get the abstractions wrong and dependencies needlessly intertwined and if on top of this, you build tests that solidify these wrong assumptions, these tests will cause friction for refactoring and you might get stuck early in dead ends.
Hierarchical architecture is also harder to draw on a whiteboard, making it less visual. However, when it comes to programs, we've a long time ago moved away from flow chart diagrams referencing lots of global variables that map to languages like BASIC.
We now describe programs in languages with much better scoping. We can do the same thing in the architectural world to get similar benefits.
It's often a bit of a fine line to walk. If the domain is simple enough or the team already has a very deep understanding of all its edge cases, you might be able to jump to the right high level abstractions right from the get go and it might not be detrimental to break out and isolate logic early and make it available in broader scopes. But this should not be the default. It should be something that is earned from accumulating deep expertise about the domain.
Top level logic is ok if it's solid, mature and stable. In the same way that using global variables is much more acceptable if you slap a const in front of it, top level blocks are ok when innovation is mostly done, when they are not expected to change much.
Always remember that reducing dependency lengths and inlining is meant to achieve lower description length so if inlining significantly increases the overall size of a program because of repetition, you probably shouldn't be doing it. There's a trade-off between stretching out dependencies and deduplication. And most of the time, it is worth following DRY. There are however cases where you need multiple variants of a function for different parts of a system where it might make more sense for each part to keep its own version instead of trying to make a more broadly available generic or configurable function that will be difficult to modify for one purpose without affecting the other use. When breaking out code, minimize dependency lengths by breaking out into the next closest scope, not further than needed.
There recently was a hacker news discussion about keeping things inline, "Don't DRY Your Code Prematurely" which argued along the same lines but didn't really go into how to make the decision of when it's no longer premature to break out code. It's sometimes a tough decision to make but there are real theoretical principles behind these decisions and you can build intuition by understanding these principles.
Breaking out a block of code into a function just so that the function name can act as a comment is unnecessary. Just add the comment.
Testing a piece of logic in isolation can be a reason for breaking out code to the next scope, it might reduce the implementation length of tests, but always consider the trade-offs compared to testing as part of some kind of integration test instead of a broken out unit. One question to ask yourself: does it help to reduce the overall size of logic plus tests to break something out? Does it make it sufficiently easier to test, to separate the unit that it's worth the hit to dependency lengths? Often it does, but not always! Also onsider how other features might prematurely couple to your feature via this broken out function once it's in a broader scope.
A lot of these principles apply beyond programming, it applies anywhere where knowledge needs to be organized. Software abstractions with better problem-solution fit is similar to the concept of product-market fit. And there's even lessons for people organizations. Things like "get out of the office", "talk to your customer" "lean" principles or "Day 1 Culture", "forward deployed engineers" are meant to minimize the distance between customer and decision makers that larger company departmental modularization tends to create. The battle against entropy is everywhere. Build your organization hierarchy to minimize distance of important relationships and constantly rebalance the tree to fit new prioritites.
Here's a bit of wild conjecture to end this post. I'm getting speculative here and haven't worked things out very well but, I italicized the word effect above for a reason.
Dependency minimization schemes, Solomonoff/Kolmogorov complexity, seem to have something to do with causal reasoning. This would explain why LLMs became powerful when they started to sort out dependency trees. They started to think more along the lines of causality. Dependency trees seem to have some kind of relation to causal graphs used in causal inference.
Causality in statistics is about counterfactuals, hypotheticals, "what if" scenarios. It is specifically about generalizing to the unknown. Causality is a property of models. It's not something physical in the universe. There is no cause particle. It's a (seemingly powerful) way of reasoning about things. "What if" scenarios are scenarios outside but adjacent to what you have data on. They are about making predictions about things that you might not have seen happening but are still able to predict based on observations plus small "interventions" on the implied model. Extending reasoning beyond what you have data about might be one of the main purposes of causal reasoning, the exact same thing that MDL promises.
It's not difficult to imagine that the small interventions used in causal models might work better along paths of minimized dependencies. Reducing dependency lengths might be related to finding those paths optimal to do causal reasoning (ChatGPT seems to aggree).
Acknowledgements: Multiple people gave me feedback and suggestions on this post. I want to thank: Marcus Boorstin, Aaron Lefkowitz, Dan Toye, Vlad Iovanov, Dharam Lietz, Mark Erdman, Grant Oladipo And Joe Hines.
[1] Let me back up and attempt to illustrate some relevant concepts with with an ML example. One of algorithm that is most prone to overfitting and poor generalization is k-nearest neighbor. Overfitting means that your algorithm works really well on your training data but doesn't generalize to unknown data. k-NN is a simple algorithm, it builds a database of training data points, and when you want to make a prediction for a new data point, it looks up the k data points that are most similar based on some similarity metric (like cosine vector product) and makes a prediction based on the retrieved most similar data point(s). k-NN, especially 1-NN has a tendency to completely overfit test data.
When training ML algorithms with data, you'll often have a limited amount of data and you want to train with the most data possible so you can have the best performance. However, then, you don't have any data left for testing. Some people will test with the training data and it'll give an idea of performance for some algorithms but for 1-NN, the algorithm will simply retrieve the original data points and predict their exact value and get 100% accuracy regardless of how well the algorithm would perform in the real world. I've seen this in university projects. "We used k-NN and got 100% accuracy. Yay!". Using your training data for testing is usually just fooling yourself as it won't get that performance on new data. The equivalent in software would be a program that works perfectly to specifications and passes all unit tests but that fails when facing real world problems.
There are ways to get better estimates of accuracy through cross validation, often schemes where you train on a part of the data and keep another portion for testing. In software, you can work with customers and test on real world scenarios.
But there are also algorithms that tend to simply overfit less, usually by doing things in a more Bayesian way, taking into account uncertainty due to the amount of data being limited, recognizing that data available consists only of a subsample of a greater population, and by building abstractions that generalize better and better represent your state of knowledge.